🔴Towards End-to-end Video-based Eye-Tracking
CVPR 2020
1、Abstract & Intro
基本想法:
人眼观察区域往往是屏幕上的显著性区域,这就可以当成一个特征输入网络。
贡献:
提出了一个数据集EVE,创造了一个新的baseline
提出一个网络,GazeRefineNet,解决了以往引入屏幕图像容易过拟合的问题,误差2.40°,欧氏距离2.75cm误差,比不考虑屏幕内容高了28%
2、Related Work
Remote Gaze Estimation
最近用机器学习解决Gaze Estimation问题,允许更大的头部姿态变化,跨个人视线估计,也就是在没见过的人身上直接应用。也有用贝叶斯学习的。
本文强调了数据集的重要性,提到了RT-GENE数据集,但是不是为屏幕视线估计设计的;也提到了DynamicGaze数据集,但是没开源。EVE很牛,54位参与者,1230万frame和一套视觉刺激。
Temporal Models for Gaze Estimation
时序模型是一个新话题,最出的工作展示了如何用RNN联合CNN进行特征提取。景观屏幕的Gaze Estimation没什么改进,但在EYEDIAP数据集上效果令人鼓舞。作者的视频数据集包括时间同步的屏幕记录,用户面对的摄像头,和眼睛凝视数据。
Refining Gaze Estimates
有的方法使用预训练模型,对个人进行微调,性能提升不错,但是微调就是问题。
对于屏幕,就可以考虑屏幕内容显著性,并与预测人眼PoG的模型对齐,提高准确性。问题是容易过拟合,于是作者建议用屏幕内容和最初的实现估计来更准确地惊喜话最终的实现估计。
3、EVE Dataset
比较了EVE数据集和常用的MPIIGaze和GazeCapture,得出了EVE在视线方向和头部方向有着更好的表现。
4、Method
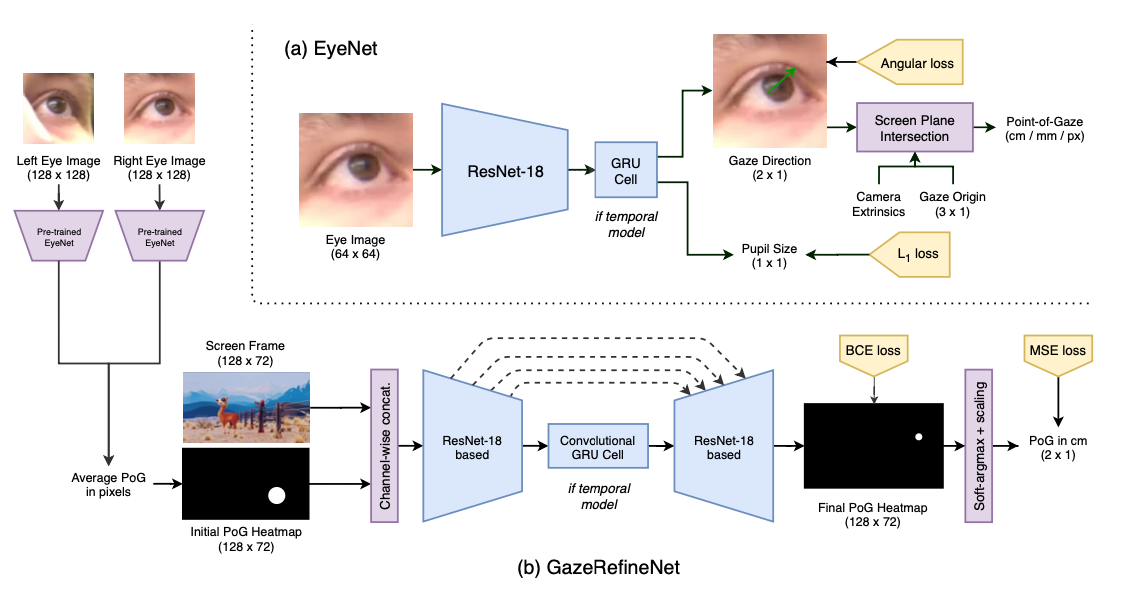
首先介绍EyeNetstatic与其递归版本EyeNetRNN, EyeNetLSTM, EyeNetGRU,再介绍GazeRefineNet。
4.1 EyeNet Architecture
Gaze预测结果通过三维方向向量或者球坐标系中的欧拉角输出。
角度损失函数为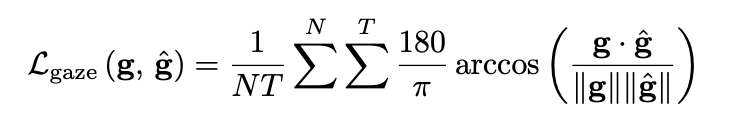
一个batch为N个长度为T的向量。
PoG损失函数如下:
PoG的预测用的是ResNet18,为了引入递归,可选择加入RNN,LSTM,GRU块。
4.2 GazeRefineNet Architecture
给定人的左右眼图像xl和xr,f为EyeNet,sl = f(xl), sr = f(xr),s~为sl和sr的算数平均。
g为一个FNC,s = g(xS,s~),x_S就是屏幕内容。这就是引入了屏幕图像来修正PoG。沿用相同的逻辑,我们将我们的初步PoG估计 s~表示为一个置信度图。
为了利用时序信息,采用了GRU cell。
Train Trick:可选地在编码器和解码器层之间加入连接跳跃连接,因为这在FCN中被证明是有帮助的。通过在输出热图上使用逐像素的二进制交叉熵损失和在最终数值估计的PoG上使用MSE损失来训练GazeRefineNet,PoG被转换为厘米,以防止损失项因其大小而爆炸。
问题:可能会发现训练集和验证集上的差异比较大,这和超参数的设置以及过拟合无关,造成的原因是个体之间眼睛光学轴和视觉轴有一个偏移,被称为kappa参数,且虽然光学轴可以被光学仪器测量,视觉轴没法被测量。由于模型没有对这个参数的设计,所以这个东西被吃掉了,所以对个人来说3°,泛化5°。如果可以提供额外信号(x_S),网络应该可以克服这个困难。作者把这个东西叫Offset Augmentation。
5、 Results
5.1 Eye Gaze Estimation
作者经过比较发现,EyeNet的GRU和LSTM变体在视线估计误差和瞳孔大小误差都有最好的表现。
GazeRefineNet在加入了视频显著性作为输入后,视线估计的误差得到了改善,并且发现加入Screen Content,Offset Augmentation,Skip Conn后,网络的性能在视线估计方面和PoG估计方面都存在较大的提升。
5.2 Screen Content based Refinement of PoG
评估GazeRefineNet和现有的基于显著性的方法进行比较的时候,作者的网络的表现也要优于之前最先进的UNISAL方法。
实验过程:
5.2 Screen Content based Refinement of PoG
GazeRefineNet consists of a fully-convolutional architecture which takes as in- put a screen content frame, and an offset augmentation procedure at training time. Our baseline performance for this experiment is different to Tab. 2 as gaze errors are improved when averaging the PoG from the left and right eyes, with according adjustments to the label (averaged in screen space). Even with the new competitive baseline from PoG averaging, we find in Tab. 3 that each of our additional contributions yield large performance improvements, amounting to a 28% improvement in gaze direction error, reducing it to 2.49◦. While not directly comparable due to differences in setting, this value is lower even than recently reported performances of supervised few-shot adaptation approaches on in-the- wild datasets [37,29]. Specifically, we find that the offset augmentation procedure yields the greatest performance improvements, with temporal modeling further improving performance. Skip connections between the encoder and decoder do not necessarily help (except in the case of GazeRefineNetRNN), presumably be- cause the output relies mostly on information processed at the bottleneck. We present additional experiments of GazeRefineNet in the following paragraphs, and describe their setup details in our supplementary materials.
5.2 基于屏幕内容的PoG细化
GazeRefineNet由一个完全卷积的架构组成,该架构在训练时接收一个屏幕内容帧作为输入,并进行偏移增强过程。我们此实验的基准性能与表2不同,因为当从左右眼平均PoG时,注视误差得到改善,并相应调整标签(在屏幕空间中取平均)。即使采用了新的竞争基线来自PoG平均值,我们发现在表3中,我们额外贡献的每一项都带来了较大的性能提升,将注视方向误差提高了28%,降低至2.49°。虽然由于设置上存在差异而无法直接比较,在野外数据集上监督式少样本适应方法最近报告的性能甚至低于这个数值[37,29]。具体地说,我们发现偏移增强过程带来了最大的性能提升,并且时间建模进一步改善了性能。编码器和解码器之间跳跃连接并不一定有所帮助(除非是对于GazeRefineNetRNN),可能是因为输出主要依赖于在瓶颈处处理过的信息。我们将在以下段落中展示更多关于GazeRefineNet 的实验,并在补充材料中描述其设置详情。
Comparison to Saliency-based Methods. In order to assess how our GazeRefineNet approach compares with existing saliency-based methods, we im- plement two up-to-date methods loosely based on [1] and [48]. First, we use the state-of-the-art UNISAL approach [12] to attain high quality visual saliency predictions. We accumulate these predictions over time for the full exposure du- ration of each visual stimulus in EVE (up to 2 minutes), which should provide the best context for alignment (as opposed to our online approach, which is lim- ited to 3 seconds of history). Standard back propagation is then used to optimize for either scale and bias in screen-space (similar to [1]) or the visual-optical axis offset, kappa (similar to [48]) using a KL-divergence objective between accu- mulated visual saliency predictions and accumulated heatmaps of refined gaze estimates in the screen space. Tab. 4 shows that while both saliency-based base-lines perform respectably on the well-studied image and video stimuli, they fail completely on wikipedia stimuli despite the fact that the saliency estimation model was provided with full 1080p frames (as opposed to the 128 × 72 input used by GazeRefineNetGRU). Furthermore, our direct approach takes raw screen pixels and gaze estimations up to the current time-step as explicit conditions and thus is a simpler yet explicit solution for live gaze refinement that can be learned end-to-end. Both the training of our approach and its large-scale evaluation is made possible by the EVE, which should allow for insightful comparisons in the future.
与基于显著性的方法进行比较。为了评估我们的GazeRefineNet方法与现有基于显著性的方法相比如何,我们实现了两种最新方法,它们松散地基于[1]和[48]。首先,我们使用最先进的UNISAL方法[12]来获取高质量的视觉显著性预测。我们将这些预测随时间累积,在EVE中每个视觉刺激的完整曝光持续时间内(长达2分钟),这应该为对齐提供最佳背景(与我们在线方法不同,后者仅限于3秒历史)。然后使用标准反向传播来优化屏幕空间中尺度和偏差(类似于[1])或者视觉-光轴偏移kappa(类似于[48]),使用累积视觉显著性预测和在屏幕空间中精炼注视估计热图之间KL散度目标函数。表4显示,虽然两种基于显著性的基线在经过深入研究的图像和视频刺激上表现可观,但它们在维基百科刺激上完全失败,尽管给定了全分辨率1080p帧作为输入模型(而非GazeRefineNetGRU所用的128×72输入)。此外,我们直接处理方式以当前时间步之前原始屏幕像素和注视估计作为明确条件,并因此是一种更简单但明确解决方案用于实时注视精炼学习端到端。通过EVE使得我们能够训练该方法并进行大规模评估,并且未来应该可以进行深入比较。
Cross-Stimuli Evaluation. We study if our method generalizes to novel stim- uli types, as this has previously been raised as in issue for saliency-based gaze alignment methods (such as in [42]). In Tab. 5, we confirm that indeed training and testing on the same stimulus type yields the greatest improvements in gaze direction estimation (shown in diagonal of table). We find in general that large improvements can be observed even when training solely on video or wikipedia stimuli types. One assumes that this is the case due to the existence of text in our video stimuli and the existence of small amounts of images in the wikipedia stimulus. In contrast, we can see that training a model on static images only does not lead to good generalization on the stimuli types.
交叉刺激评估。我们研究了我们的方法是否能推广到新颖的刺激类型,因为这在基于显著性的凝视对齐方法中曾被提出过(例如[42]中)。在表5中,我们确认确实训练和测试相同类型的刺激会使凝视方向估计得到最大改进(显示在表格对角线上)。总体而言,即使仅在视频或维基百科刺激类型上进行训练也可以观察到较大的改进。人们认为这是由于视频刺激中存在文本以及维基百科刺激中存在少量图像导致的。相反,我们可以看到仅在静态图像上训练模型并不能很好地推广至各种类型的刺激。
Qualitative Results. We visualize our results qualitatively in Fig. 4. Specifi- cally, we can see that when provided with initial estimates of PoG over time from EyeNetGRU (far-left column), our GazeRefineNetGRU can nicely recover person-specific offsets at test time to yield improved estimates of PoG (center column). When viewed in comparison with the ground-truth (far-right column), the suc- cess of GazeRefineNetGRU in these example cases is clear. In addition, note that the final operation is not one of pure offset-correction, but that the gaze signal is more aligned with the visual layout of the screen content post-refinement.
定性结果。我们在图4中以定性方式展示了我们的结果。具体来说,我们可以看到当EyeNetGRU提供随时间变化的PoG的初始估计时(最左列),我们的GazeRefineNetGRU能够在测试时很好地恢复特定于人员的偏移量,从而产生改进后的PoG估计值(中间列)。与地面真相进行比较时(最右列),在这些示例情况下,GazeRefineNetGRU的成功是明显的。此外,请注意最终操作不仅仅是纯粹的偏移校正,而且经过改进后,凝视信号更加与屏幕内容视觉布局对齐。
Last updated